Caractéristiques de l'architecture GeForce 4 Ti 4200
Principales innovations architecturales du NV25 (par rapport à NV20)
Deux contrôleurs d'affichage indépendants (CRTC). Prise en charge flexible de divers modes avec la sortie de deux tampons de trame indépendants en résolution et en contenu vers tous les récepteurs de signal disponibles.
Deux RAMDAC 350 MHz à part entière intégrés dans la puce (avec une palette de 10 bits).
Interface de sortie TV intégrée à la puce.
Transmetteur TDMS intégré à la puce (pour interface DVI).
Deux blocs pour interpréter et exécuter les vertex shaders. Ils promettent une augmentation significative de la vitesse de traitement des scènes à géométrie complexe. Les blocs ne peuvent pas utiliser différents shaders de microcode, le seul but d'une telle duplication - traiter deux sommets en même temps - est d'augmenter les performances.
Les pipelines de rendu améliorés fournissent une prise en charge matérielle des pixel shaders jusqu'à la version 1.3 incluse.
Selon NVIDIA, le taux de remplissage effectif dans les modes MSAA a été augmenté, désormais les modes 2x AA et Quincunx AA entraîneront une baisse de performances nettement inférieure. Quincunx AA légèrement amélioré (positions d'échantillonnage décalées). Une nouvelle méthode AA est apparue - 4xS.
Système de cache séparé amélioré (4 caches séparés pour la géométrie, les textures, le tampon de trame et le tampon Z).
Compression avancée sans perte (1:4) et effacement rapide du tampon Z.
Algorithme de rejet de surface caché amélioré (Z Cull HSR).
En résumant cette liste, je voudrais souligner le caractère évolutif plutôt que révolutionnaire des changements par rapport à la précédente création de NVIDIA (NV20). Cependant, ce n'est pas surprenant - historiquement, NVIDIA a d'abord proposé un produit contenant de nombreuses nouvelles technologies, puis a publié une version plus avancée (optimisée) basée sur celui-ci, éliminant les lacunes qui ont attiré l'attention principale (lors de la présence du produit sur le marché).
Schéma structurel du N25
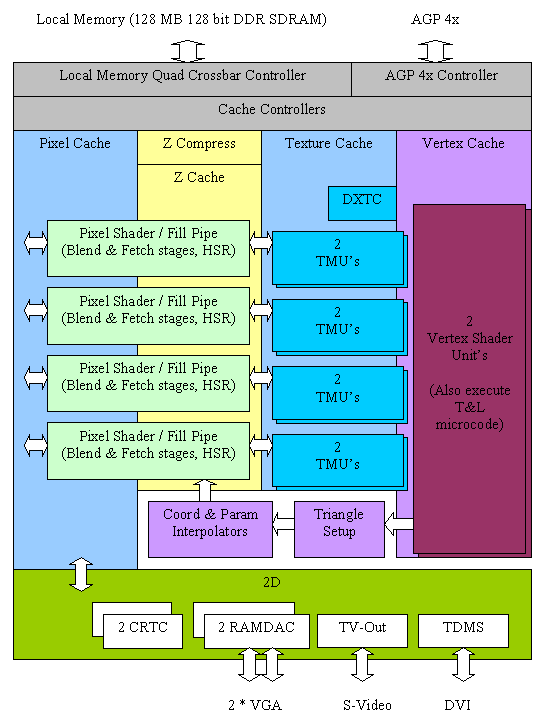
Selon les tests effectués après la sortie des cartes vidéo, la GeForce4 Ti s'est avérée nettement plus rapide que la GeForce3 Ti. Un tel écart impressionnant dans les performances du NV25 a été atteint non pas en raison d'une technologie fondamentalement nouvelle, mais en raison d'un débogage et d'un ajustement supplémentaires des technologies existantes dans GeForce3 (NV20). Rappelons que le cœur GeForce4 n'était que 5% plus gros que le cœur NV20 avec le même procédé de fabrication (0,15 µm).
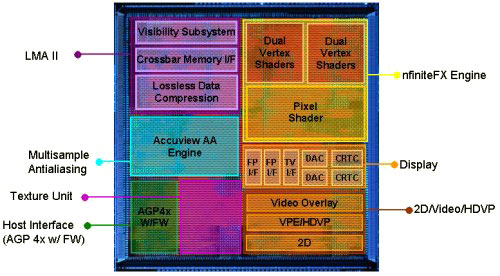
shaders de vertex nfiniteFX II
Si la GeForce3 n'avait qu'un seul module de vertex shader, alors la GeForce4 Ti en a deux. Cependant, cela ne vous surprendra probablement pas, car la puce nVidia pour Microsoft Xbox dispose également de deux modules de vertex shader. Sauf si les modules ont été améliorés en NV25.
De toute évidence, deux modules de vertex shader parallèles pourraient traiter plus de sommets par unité de temps. Pour ce faire, la puce elle-même a décomposé les sommets en deux flux, de sorte que le nouveau mécanisme est transparent pour les applications et les API. La planification des instructions est gérée par le NV25, et la puce doit s'assurer que chaque module de vertex shader fonctionne sur son propre vertex. Les améliorations apportées aux modules de vertex shader depuis la GeForce3 ont entraîné une latence plus faible dans le traitement des instructions.
En conséquence, la GeForce4 Ti4600 pourrait traiter environ 3 fois plus de vertices que la GeForce3 Ti500 en raison de la présence de deux modules de vertex shader, de leur amélioration et d'un fonctionnement à une fréquence d'horloge plus élevée.
Shaders de pixels nfiniteFX II
Nvidia a pu améliorer la fonctionnalité des pixel shaders de la GeForce4 Ti.
La nouvelle puce prend en charge Pixel Shaders 1.2 et 1.3, mais pas l'extension ATI 1.4.
Vous trouverez ci-dessous les nouveaux modes de pixel shader.
DÉCALAGE_PROJECTIVE_TEXTURE_2D_NV
DÉCALAGE_PROJECTIVE_TEXTURE_2D_SCALE_NV
OFFSET_PROJECTIVE_TEXTURE_RECTANGLE_NV
OFFSET_PROJECTIVE_TEXTURE_RECTANGLE_SCALE_NV
OFFSET_HILO_TEXTURE_2D_NV
OFFSET_HILO_TEXTURE_RECTANGLE_NV
OFFSET_HILO_PROJECTIVE_TEXTURE_2D_NV
OFFSET_HILO_PROJECTIVE_TEXTURE_RECTANGLE_NV
DEPENDENT_HILO_TEXTURE_2D_NV
DEPENDENT_RGB_TEXTURE_3D_NV
DEPENDENT_RGB_TEXTURE_CUBE_MAP_NV
DOT_PRODUCT_TEXTURE_1D_NV
DOT_PRODUCT_PASS_THROUGH_NV
DOT_PRODUCT_AFFINE_DEPTH_REPLACE_NV
Nous ne décrirons pas chaque nouveau mode, mais il convient de noter que GeForce4 Ti a introduit la prise en charge du bump mapping z-correct, ce qui a permis d'éliminer les artefacts qui apparaissaient lorsqu'une texture de bosse entrait en contact avec une autre géométrie (par exemple, lorsque l'eau dans un lac ou la rivière touche le sol).
Nvidia a finalement été en mesure d'améliorer le pipeline de pixel shader, ce qui a considérablement affecté la vitesse de rendu des scènes avec 3 à 4 textures par pixel.

Accuview - anti-aliasing amélioré Lors de la sortie de la GeForce3, nVidia a annoncé HRAA, un anti-aliasing haute résolution basé sur l'anti-aliasing plein écran multi-échantillons. La GeForce4 a introduit l'anti-aliasing Accuview, qui est essentiellement une amélioration de l'anti-aliasing multi-échantillons, à la fois en termes de qualité et de performances.
Nvidia a déplacé les positions des échantillons, ce qui devrait améliorer la qualité de l'anticrénelage en raison de l'accumulation de moins d'erreurs, en particulier lors de l'utilisation de l'anticrénelage Quincunx. Nvidia a publié une documentation sur cette procédure, mais cela n'avait guère de sens de la lire, car elle n'expliquait pas grand-chose. Une nouvelle technologie de filtrage était activée chaque fois que des échantillons étaient combinés sur la trame anti-crénelée finale, et la technologie permettait d'enregistrer une écriture complète dans le tampon de trame, ce qui à son tour affectait considérablement les performances d'anti-crénelage.
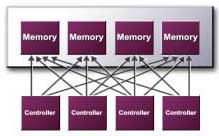
LMA II - nouvelle architecture mémoire ETC'est grâce à l'amélioration de l'architecture mémoire que la GeForce4 Ti affiche une si forte avance sur la GeForce3.
Dans GeForce3/GeForce4, le contrôleur mémoire était divisé en quatre contrôleurs indépendants, chacun utilisant un bus DDR 32 bits dédié. Toutes les demandes de mémoire étaient partagées entre ces contrôleurs.
Dans LMA II, presque tous les composants ont été améliorés. Vous pouvez faire attention à quatre caches. Mais la mise en cache est exclusive à GeForce, car la Radeon 8500 avait également des caches similaires. En général, la mise en cache dans les puces graphiques a reçu beaucoup moins d'attention que les caches dans les processeurs, car leur taille n'était pas si grande. La raison en est claire : les puces graphiques étaient alors plus lentes que les bus mémoire, tandis que les processeurs centraux étaient 2 à 16 fois plus rapides, de sorte que le cache y jouait un rôle beaucoup plus important.
Contrôleur de mémoire croisée (mémoire crossbar controls)
La GeForce3 disposait déjà de ce contrôleur, permettant une transmission 64 bits, 128 bits et normale 256 bits, ce qui a considérablement amélioré le débit. Dans LMA II, nVidia a amélioré les algorithmes d'équilibrage de charge pour différentes sections de mémoire et modernisé le schéma de priorité.
Sous-système visuel (sous-système de visibilité) - suppression des pixels superposés
Cette technologie existait déjà dans la GeForce3, mais elle a été améliorée dans la NV25 pour une suppression plus précise des pixels en utilisant moins de bande passante mémoire. Le rejet a ensuite été effectué à l'aide d'un cache spécial sur la puce, ce qui a permis de réduire l'accès à la mémoire externe de la carte vidéo. Selon les recherches d'Anandtech, la GeForce4 était 25% meilleure pour rejeter les pixels que la GeForce3 à la même vitesse d'horloge.
Compression Z-buffer sans perte
Encore une fois, cette fonctionnalité existait dans la GeForce3, mais grâce au nouvel algorithme de compression, LMA II était plus susceptible d'obtenir une compression 4: 1 réussie.
Cache de vertex
Stocke les sommets après leur envoi via AGP. Le cache a amélioré l'utilisation de l'AGP, car il nous a permis d'éviter de passer des sommets identiques (par exemple, si les primitives avaient des frontières communes).
Cache primitif
Les primitives accumulées après leur traitement (après le vertex shader) en primitives fondamentales pour le transfert vers le module de réglage des triangles.
Cache à double texture
Déjà existé sur GeForce3. Les nouveaux algorithmes fonctionnaient mieux lors de l'utilisation de la multitexturation ou du filtrage de haute qualité. Grâce à cela, GeForce4 Ti a considérablement amélioré les performances lors de l'application de 3 à 4 textures.
Cache de pixels
Le cache était utilisé à la fin du pipeline de rendu pour l'accumulation, très similaire à la fonctionnalité des processeurs Intel/AMD. Le cache a accumulé un certain nombre de pixels puis les a écrits en mode batch en mémoire.
Pré-charge automatique (pré-charge)
Avant de lire à partir de la banque de mémoire, celle-ci doit être préchargée, ce qui entraîne des retards. La GeForce4 Ti pourrait se recharger de manière proactive à l'aide d'un algorithme de prédiction spécial.
Z-clear rapide (Z-clear)
Cette fonctionnalité est connue et utilisée dans d'autres puces depuis un certain temps. La compensation Z rapide a été utilisée pour la première fois sur une puce ATI Radeon. Il définissait simplement un indicateur pour une certaine section du tampon de trame, de sorte qu'au lieu de remplir cette section avec des zéros, vous pouviez simplement définir un indicateur, ce qui économisait de la bande passante mémoire.

Spécifications NVIDIA GeForce 4 Ti 4200
| Nom | GeForce 4 Ti 4200 |
| noyau | NV25 |
| Technologie de processus (µm) | 0,15 |
| Transistors (millions) | 63 |
| Fréquence centrale | 250 |
| Fréquence mémoire (DDR) | 222 (444) |
| Type de bus et de mémoire | DDR-128 bits |
| Bande passante (Gb/s) | 7,1 |
| Canalisations de pixels | 4 |
| TMU par convoyeur | 2 |
| textures par horloge | 8 |
| textures par passe | 4 |
| Convoyeurs Vertex | 2 |
| Ombrage de pixels | 1,3 |
| Nuanceurs de vertex | 1,1 |
| Taux de remplissage (Mpix/s) | 1000 |
| Taux de remplissage (Mtex/s) | 2000 |
| DirectX | 8.0 |
| Anticrénelage (Max) | MS-4x |
| Filtrage anisotrope (Max) | 8x |
| Taille mémoire | 64 / 128 MB |
| Interface | AGP 4x |
| RAMDAC | 2x350 MHz |
La GeForce4 Ti 4200 est une version plus légère de la GeForce4 Ti 4600 ou 4400 qui avait une vitesse d'horloge inférieure mais était beaucoup moins chère.
À bien des égards, la GeForce4 Ti 4200 peut être considérée comme un "fossoyeur" potentiel de la gamme GeForce3 Ti 500. pas en faveur de cette dernière. Par conséquent, NVIDIA a reporté la sortie du Ti 4200 à une date ultérieure, jusqu'à ce qu'il y ait une baisse significative des ventes de la gamme GeForce4.
Mafia