








Caractéristiques de l'architecture GeForce GTX 280

De plus, chaque module TPC est constitué d'un ensemble de multiprocesseurs de streaming (SM, Streaming Multiprocessors), et chaque SM contient huit cœurs de processeur, également appelés processeurs de flux (SP, Streaming Processor) ou processeurs de threads (TP, Thread Processor). Chaque SM comprend également des processeurs de filtrage de texture pour le mode graphique, également utilisés pour diverses opérations de filtrage en mode calcul.
Vous trouverez ci-dessous un schéma fonctionnel de la GeForce 280 GTX en mode graphique traditionnel.

En passant en mode calcul, le gestionnaire de threads matériels (ci-dessus) gère les threads TPC.

Zoom sur le cluster TPC : mémoire partagée par SM ; chaque cœur de processeur SM peut partager des données entre d'autres cœurs SM via une mémoire distribuée, sans avoir besoin d'accéder à un sous-système de mémoire externe.
Ainsi, l'architecture de shader et d'ordinateur unifiée de NVIDIA utilise deux modèles de calcul complètement différents : pour le fonctionnement TPC, MIMD (instructions multiples, données multiples) est utilisé, pour les calculs SM - SIMT (instruction unique, thread multiple), version avancée, SIMD (instruction unique , données multiples).
Au niveau des caractéristiques générales, par rapport aux précédentes générations de puces, la famille GeForce GTX 200 présente les avantages suivants :
Capacité à traiter trois fois plus de flux de données par unité de temps
Nouvelle conception du planificateur de commandes avec 20 % d'efficacité de traitement des textures en plus
Interface mémoire 512 bits (384 bits pour la génération précédente)
Processus d'échantillonnage et de compression z optimisé pour de meilleures performances à des tailles d'écran élevées
Améliorations architecturales pour améliorer les performances de traitement des ombres
Mélange de tampon de trame à pleine vitesse (par rapport à la demi-vitesse sur la 8800 GTX)
Tampon d'instructions doublé pour des performances de calcul améliorées
Nombre de registres doublé pour un calcul plus rapide des shaders longs et complexes
Virgule flottante double précision conforme à la version IEEE 754R
Prise en charge matérielle de l'espace colorimétrique 10 bits (DisplayPort uniquement)
Voici une liste des principales caractéristiques des nouvelles puces :
Prise en charge de NVIDIA PhysX
Prise en charge de Microsoft DirectX 10, Shader Model 4.0
Prise en charge de la technologie NVIDIA CUDA
Prise en charge du bus PCI Express 2.0
Prise en charge de la technologie GigaThread
Moteur NVIDIA Lumenex
Virgule flottante 128 bits (HDR)
Prise en charge d'OpenGL 2.1
Prise en charge du DVI double liaison double
Prise en charge de la technologie NVIDIA PureVideo HD
Prise en charge de la technologie NVIDIA HybridPower
Par ailleurs, il est à noter que DirectX 10.1 n'est pas pris en charge par la famille GeForce GTX 200. La raison en est que lors du développement des puces d'une nouvelle famille, après consultation des partenaires, il était d'usage de ne pas se concentrer sur le support de DirectX 10.1, qui est encore peu demandé, mais sur l'amélioration de l'architecture et des performances des puces.
Basée sur un ensemble d'algorithmes physiques, la mise en œuvre de la technologie NVIDIA PhysX est un puissant moteur physique en temps réel. Actuellement, la prise en charge de PhysX est implémentée dans plus de 150 jeux. Combiné à un puissant GPU, le moteur PhysX offre une augmentation significative de la puissance de traitement physique, en particulier dans des domaines tels que la création d'explosions de poussière et de débris, des personnages aux expressions faciales complexes, de nouvelles armes aux effets fantastiques, des tissus usés ou déchirés de manière réaliste, du brouillard et de la fumée. avec un flux dynamique autour des objets.
De nombreux développeurs et développeurs de jeux s'efforcent depuis longtemps d'implémenter des effets physiques dans les jeux. Chaque année, cette direction devient de plus en plus pertinente. Dans les jeux modernes, l'interaction des objets avec l'environnement est réalisée par les forces de deux moteurs qui ont acquis la plus grande popularité - Havok et PhysX.
Havok est le moteur le plus ancien sur lequel de nombreux jeux sont écrits pour PC et consoles. En 2006, l'ATI alors indépendante a démontré l'accélération des effets physiques par les forces des cartes vidéo Radeon X1900XT. Cependant, Havok a ensuite été racheté par Intel, qui a déclaré que les effets physiques seraient calculés par ce moteur à l'aide de processeurs.

PhysX a été développé par AGEIA, qui a mis en œuvre la "physique" avec des accélérateurs de sa propre conception. Mais il se trouve que, malgré la grande popularité de ce moteur auprès des développeurs de jeux, l'implémentation d'effets physiques dans les jeux par des accélérateurs spécialisés s'est avérée très controversée.
Et l'année dernière, NVIDIA a acheté AGEIA PhysX. Une déclaration a été faite selon laquelle grâce à l'optimisation des pilotes, le moteur PhysX sera adapté à l'utilisation des cartes vidéo GeForce 8800GT et supérieures.
Une autre innovation importante est les nouveaux modes d'économie d'énergie. En utilisant une technologie de traitement de précision à 65 nm et de nouvelles solutions de circuit, un contrôle de puissance plus flexible et dynamique a été obtenu. Ainsi, la consommation de la famille de puces graphiques GeForce GTX 200 en mode veille ou en mode 2D est d'environ 25 W ; lors de la lecture d'un film DVD Blu-ray - environ 35 W; à pleine charge 3D, le TDP ne dépasse pas 236 watts. La puce graphique GeForce GTX 200 peut être complètement désactivée grâce à la prise en charge de la technologie HybridPower avec des cartes mères basées sur des chipsets nForce HybridPower avec des graphiques intégrés (par exemple, nForce 780a ou 790i), tandis que le flux graphique à faible intensité est simplement traité par le GPU intégré à la carte mère. De plus, les GPU de la famille GeForce GTX 200 disposent également de modules spéciaux de gestion de l'alimentation conçus pour éteindre les unités GPU qui ne sont pas actuellement utilisées.

L'utilisateur peut configurer un système basé sur deux ou trois cartes vidéo de la famille GeForce GTX 200 en mode SLI lorsqu'il utilise des cartes mères basées sur les chipsets nForce correspondants. Dans le mode SLI standard traditionnel (avec deux cartes vidéo), une augmentation des performances d'environ 60 à 90 % dans les jeux est déclarée ; en mode SLI 3 voies - le nombre maximal d'images par seconde à des tailles d'écran maximales.
Dans le cadre de l'annonce de la nouvelle famille de GPU GeForce GTX 200, NVIDIA propose un tout nouveau regard sur le rôle du CPU et du GPU dans le système de bureau équilibré moderne. Un tel PC optimisé, basé sur le concept de calcul hétérogène (c'est-à-dire le calcul d'un flux de tâches hétérogènes hétérogènes), selon les experts de NVIDIA, possède une architecture beaucoup plus équilibrée et un potentiel de calcul nettement supérieur. Cela fait référence à la combinaison d'un processeur aux performances relativement modérées avec les graphiques les plus puissants ou même le système SLI, qui permet des performances de pointe dans les jeux, les applications 3D et multimédias les plus exigeants.
D'autre part, le calcul intensif à l'aide de cartes graphiques modernes n'est pas nouveau depuis longtemps, mais c'est avec l'avènement de la famille de processeurs graphiques GeForce GTX 200 que NVIDIA s'attend à une augmentation significative de l'intérêt pour la technologie CUDA.
CUDA (Compute Unified Device Architecture) est une architecture informatique visant à résoudre des problèmes complexes dans les domaines grand public, commercial et technique - dans toutes les applications gourmandes en données utilisant des GPU NVIDIA. Du point de vue de la technologie CUDA, la nouvelle puce graphique GeForce GTX 280 n'est rien de plus qu'un puissant processeur multicœur (des centaines de cœurs !) pour le calcul parallèle.
Comme mentionné ci-dessus, le cœur graphique de la famille GeForce GTX 200 peut être considéré comme une puce prenant en charge les modes graphiques et informatiques. Dans l'un de ces modes - "informatique", la même GeForce GTX 280 se transforme en un multiprocesseur programmable avec 240 cœurs et 1 Go de mémoire dédiée - une sorte de supercalculateur dédié aux performances téraflopiques, ce qui augmente considérablement les performances des applications qui parallélisent bien les données , par exemple, l'encodage vidéo, le calcul scientifique, etc.
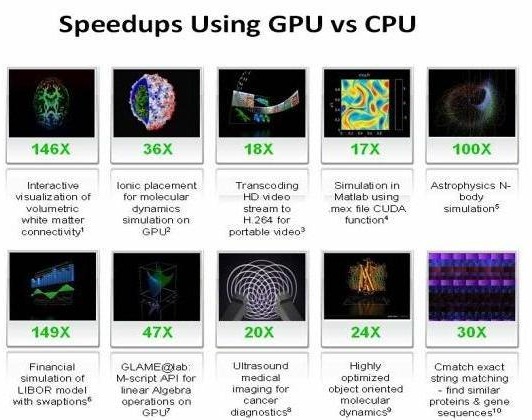
Les familles de processeurs graphiques GeForce 8 et 9 ont été les premières sur le marché à prendre en charge la technologie CUDA, avec plus de 70 millions d'unités vendues, et l'intérêt pour le projet CUDA ne cesse de croître. Apprenez-en plus sur le projet et téléchargez les fichiers dont vous avez besoin pour commencer ici. À titre d'exemple, les captures d'écran ci-dessous montrent des exemples de gains de performances de calcul obtenus par des utilisateurs indépendants de la technologie CUDA.
Comparé à l'ancien leader GeForce 8800 GTX, le nouveau produit phare GeForce GTX 280 a 1,88 fois plus de cœurs de processeur ; capable de traiter environ 2,5 threads supplémentaires par puce ; a deux fois la taille des registres de fichiers et prend en charge les calculs en virgule flottante à double précision; prend en charge 1 Go de mémoire avec une interface 512 bits ; équipé d'un répartiteur de commandes plus efficace et de capacités de communication améliorées entre les éléments de puce; tampon Z et module de compression améliorés, prise en charge de la palette de couleurs 10 bits, etc.
Pour la première fois, une nouvelle génération de puces GeForce GTX 200 se positionne initialement non seulement comme un puissant accélérateur graphique 3D, mais aussi comme une solution informatique sérieuse pour le calcul parallèle.
Spécifications NVIDIA GeForce GTX 280
| Nom | GeForce GTX 280 |
| noyau | GT200 (D10U-30) |
| Technologie de processus (µm) | 0.065 |
| Transistors (millions) | 1400 |
| Fréquence centrale | 602 |
| Fréquence mémoire (DDR) | 1107 |
| Type de bus et de mémoire | GDDR3 512 bits |
| Bande passante (Gb/s) | 141,67 |
| Blocs de shaders unifiés | 240 |
| Fréquence des unités de shader unifiées | 1296 |
| TMU par convoyeur | 80 |
| ROP | 32 |
| Modèle de nuanceur | 4.0 |
| Taux de remplissage (Mtex/s) | 48160 |
| DirectX | 10 |
| Interface | PCIe 2.0 |
La révolution n'a pas eu lieu, le nouveau GPU GT200 et la carte vidéo GeForce 280GTX (285GTX , 295GTX) testés aujourd'hui sont un développement ultérieur de l'architecture de shader unifiée de NVIDIA. Le nouveau GPU contient plus de blocs fonctionnels que ses prédécesseurs, ce qui lui donne le droit d'être qualifié de GPU le plus puissant à ce jour.