








GeForce GTX 960

Avec la carte graphique GeForce GTX 960, NVIDIA a apporté les avantages de l'architecture "Maxwell" au marché grand public. Les cartes vidéo ont reçu des avantages architecturaux tels que la compression de la mémoire, DSR, MFAA, VXGI et DirectX 12. Pour NVIDIA, ses propres API GameWorks et PhysX deviennent de plus en plus importantes, il n'y a pas encore de nouvelles à ce sujet, mais les acheteurs de la GeForce GTX 960 seront bénéficient également de leur soutien.
La carte vidéo GeForce GTX 960 utilise le GPU GM206, probablement pas dans sa version complète - sous le marquage GM206-300-A1. La puce est équipée de 2,94 milliards de transistors, elle est nettement moins complexe que "Tahiti" ou "Tonga" d'AMD. Étant donné que la carte vidéo GeForce GTX 960 de référence n'est pas présentée, les informations sur la fréquence de base et le Boost dans le tableau ci-dessus n'ont aucune importance pratique. NVIDIA répertorie une horloge de base de 1.126 MHz et une horloge GPU Boost de 1.178 MHz. NVIDIA a défini 2.048 Mo de mémoire GDDR5 à 1.750 MHz, la mémoire est connectée via une interface 128 bits. Le résultat est une bande passante mémoire de 112,2 Go/s, ce qui est peu par rapport à la concurrence. Mais n'oubliez pas que NVIDIA utilise une technologie de compression mémoire qui augmente théoriquement la bande passante mémoire effective, mais les 148,8 Go/s promis par NVIDIA sont encore rarement atteints.
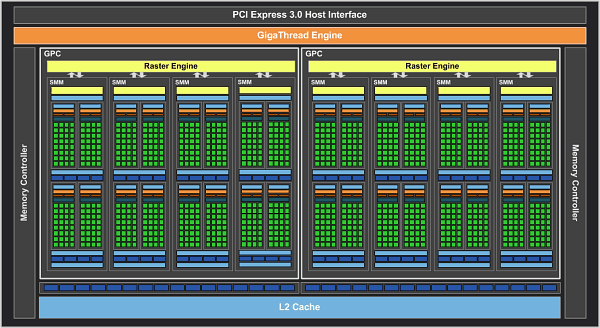
Le GPU GM206 est basé sur 1.024 processeurs de flux, qui sont combinés en huit blocs SMM (multiprocesseurs de streaming), 4x 32 processeurs de flux chacun. Quatre SMM constituent un cluster GPC, nous obtenons deux de ces clusters par GPU. 8 (SMM) x 4 (unités SMM) x 32 processeurs de flux donnent juste 1.024 XNUMX processeurs de flux.
Chaque SMM utilise huit unités de texture. Ainsi, huit SMM pour la GeForce GTX 960 donnent 64 unités de texture. Deux contrôleurs de mémoire 64 bits sont connectés à 32 pipelines d'opérations raster (ROP).
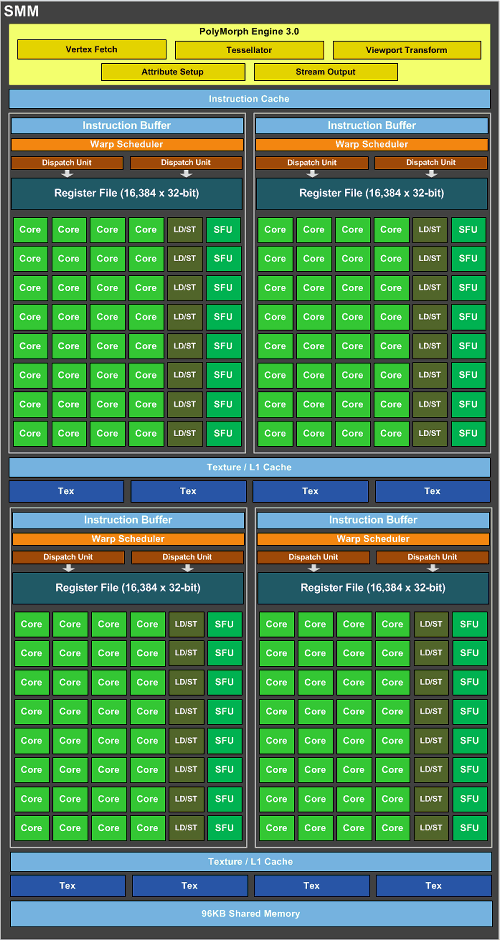
NVIDIA a pu atteindre une plus grande efficacité de Maxwell grâce à plusieurs solutions. Le cache L2 dans l'architecture "Maxwell" a été augmenté à 2.048 Ko contre 256 Ko dans l'architecture "Kepler". La bande passante du cache est restée à 512 octets par horloge. Par rapport à l'architecture Maxwell de première génération, la mémoire totale de chaque SMM a été légèrement augmentée. Maintenant, c'est déjà 96 ko, pas 64 ko. On peut également noter le nouveau Polymorph Engine version 3.0.
Le moteur PolyMorph 3.0 est responsable des requêtes de texture, de la tessellation, de la définition des attributs, de la transformation du champ de vision et de la sortie en continu. Les résultats des calculs du cluster SMM et du moteur PolyMorph 3.0 sont ensuite passés au moteur de rastérisation. À la deuxième étape, le tessellateur commence à calculer les positions des surfaces, en fonction de la distance, le niveau de détail requis est sélectionné. Les valeurs ajustées sont envoyées au cluster SMM, où les shaders de domaine et de géométrie fonctionnent avec eux. Le shader de domaine calcule la position finale de chaque triangle en fonction des shaders Hull et des tessellators. A ce stade, les cartes de déplacement sont superposées. Le shader de géométrie compare ensuite les données calculées avec les objets réellement visibles et renvoie les résultats au moteur de tessellation pour le calcul final. À la dernière étape, le moteur PolyMorph 3.0 effectue la transformation du champ de vision et la correction de la perspective. Enfin, les données calculées sont sorties via une sortie de flux, la mémoire est libérée pour d'autres calculs.
Passons aux blocs individuels du multiprocesseur SMM. Chaque bloc de 32 processeurs de flux est équipé d'un tampon d'instructions et d'un ordonnanceur warp. Les deux répartiteurs fonctionnent chacun avec 16.384 32 registres 192 bits. En regardant l'architecture "Kepler", il y avait 65.536 processeurs de flux exécutant quatre ordonnanceurs de distorsion et huit unités de répartition, pour un total de 32 512 registres 341 bits. Théoriquement, pour chaque processeur de flux dans l'architecture Maxwell, il y a 35 registres, à Kepler leur nombre était d'environ XNUMX. Cette mesure a également contribué à une augmentation des performances des processeurs de flux jusqu'à XNUMX%.
Spécifications GeForce GTX 960
|
|
||||||
|
Chip
|
||||||
|
Des fréquences
|
||||||
|
Mémoire
|
||||||
|
Interface et TDP
|
De plus, le rapport entre les processeurs de flux et les unités fonctionnelles dites spéciales (Special Function Units, SFU) a quelque peu changé. Dans l'architecture "Kepler", le rapport était de 6/1, dans "Maxwell", il est tombé à 4/1. Il en va de même pour le rapport entre les processeurs de flux et les unités de lecture/écriture (Load/Store, LD/ST). Les blocs de calcul spéciaux à double précision ne sont pas représentés dans le diagramme, ils seront très probablement présentés dans le GPU GM210 (similaire à GK110 et GK104). Mais, selon NVIDIA, le rapport entre simple et double précision est de 1/24, tout comme dans les puces "Kepler" de première génération (GK104).
De petits changements par rapport à l'implémentation précédente de l'architecture "Maxwell" ont eu lieu dans le moteur de traitement vidéo (Video Engine). Désormais, il fournit non seulement l'encodage matériel en H.265, mais également le décodage matériel. Les GeForce GTX 980 et GeForce GTX 970 manquaient également de prise en charge HDCP dans HDMI 2.2, tandis que la GeForce GTX 960 et le GPU GM206 l'ont ajouté.